


Отбор необходимых данных по условиям в Pandas
- 11.11.2023
- 2412
- Библиотеки Python
- Pandas
Фильтрация данных — ключевой этап в процессе обработки и анализа данных. С помощью библиотеки Pandas можно легко отфильтровать данные, используя условные операторы или метод query(). Давайте подробно рассмотрим эти методы на примерах.
Основы фильтрации с условными операторами
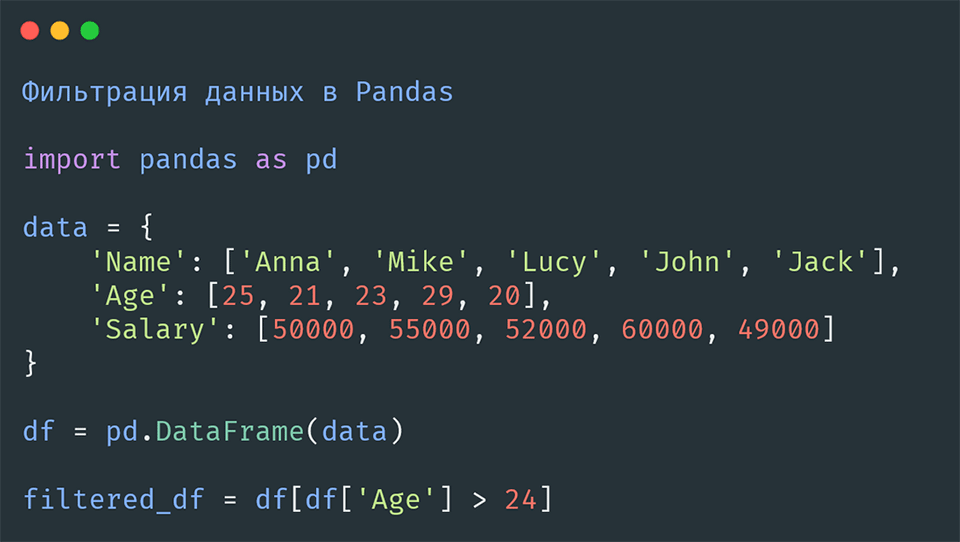
Для начала создадим простой DataFrame:
import pandas as pd
data = {
'Name': ['Anna', 'Mike', 'Lucy', 'John', 'Jack'],
'Age': [25, 21, 23, 29, 20],
'Salary': [50000, 55000, 52000, 60000, 49000]
}
df = pd.DataFrame(data)Чтобы отфильтровать людей старше 24 лет:
filtered_df = df[df['Age'] > 24]
print(filtered_df)
# Name Age Salary
# 0 Anna 25 50000
# 3 John 29 60000Использование нескольких условий
Для комбинации условий используйте & (и), | (или) и ~ (не):
# Люди старше 24 лет и зарплата больше 52000
filtered_df = df[(df['Age'] > 24) & (df['Salary'] > 52000)]
print(filtered_df)
# Name Age Salary
# 3 John 29 60000Метод query()
Если вы предпочитаете более читаемый синтаксис или работаете с большим количеством условий, query() может быть удобным вариантом:
filtered_df = df.query("Age > 24 and Salary > 52000")
print(filtered_df)
# Name Age Salary
# 3 John 29 60000Использование переменных в query()
Для использования переменных в запросе, используйте символ @:
min_age = 24
filtered_df = df.query("Age > @min_age")
print(filtered_df)
# Name Age Salary
# 0 Anna 25 50000
# 3 John 29 60000Фильтрация с использованием списков
Допустим, у вас есть список имен, и вы хотите отфильтровать только те строки, которые содержат эти имена:
names_list = ['Anna', 'John']
filtered_df = df[df['Name'].isin(names_list)]
print(filtered_df)
# Name Age Salary
# 0 Anna 25 50000
# 3 John 29 60000Фильтрация с пропущенными значениями
Для фильтрации строк с пропущенными значениями или без них используйте методы isna() и notna():
df['Bonus'] = [None, 1000, None, 1500, None]
# Фильтрация строк с пропущенными бонусами
no_bonus_df = df[df['Bonus'].isna()]
print(no_bonus_df)
# Name Age Salary Bonus
# 0 Anna 25 50000 NaN
# 2 Lucy 23 52000 NaN
# 4 Jack 20 49000 NaNФильтрация с помощью строковых методов
Pandas предоставляет ряд строковых методов, которые могут быть полезны при фильтрации:
# Фильтрация имен, начинающихся на 'A'
filtered_df = df[df['Name'].str.startswith('A')]
print(filtered_df)
# Name Age Salary
# 0 Anna 25 50000Фильтрация по регулярным выражениям
Pandas также позволяет использовать регулярные выражения для фильтрации строковых данных. Это особенно полезно, когда у вас есть сложные условия для текстовых данных.
# Отфильтровать имена, содержащие буквенное сочетание "nn"
filtered_df = df[df['Name'].str.contains('nn', regex=True, na=False)]
print(filtered_df)
# Name Age Salary
# 0 Anna 25 50000Фильтрация с помощью пользовательских функций
Вы можете использовать apply() вместе с пользовательскими функциями для более сложной фильтрации:
def custom_filter(row):
return row['Age'] > 20 and 'a' in row['Name']
filtered_df = df[df.apply(custom_filter, axis=1)]
print(filtered_df)
# Name Age Salary
# 0 Anna 25 50000Фильтрация с помощью between
Метод between() позволяет легко фильтровать данные, которые находятся в определенном диапазоне:
# Отфильтровать строки, где возраст между 21 и 25 (включительно)
filtered_df = df[df['Age'].between(21, 25)]
print(filtered_df)
# Name Age Salary
# 0 Anna 25 50000
# 1 Mike 21 55000
# 2 Lucy 23 52000Использование eval() для фильтрации
Метод eval() позволяет быстро оценивать выражения, используя строковый синтаксис:
filtered_df = df[df.eval("Age > 24 and Salary > 52000")]
print(filtered_df)
# Name Age Salary
# 3 John 29 60000Сортировка после фильтрации
Часто после фильтрации может потребоваться сортировка:
filtered_sorted_df = df[df['Age'] > 24].sort_values(by='Salary', ascending=False)
print(filtered_sorted_df)
# Name Age Salary
# 3 John 29 60000
# 0 Anna 25 50000Заключение
При работе с данными в Pandas важно знать различные методы фильтрации, чтобы быстро и эффективно отбирать необходимую информацию. Надеюсь, представленные примеры помогут вам в вашей работе с данными.
Содержание:


