



Определение уникальных элементов в Pandas: unique() и nunique()
- 10.11.2023
- 1587
- Библиотеки Python
- Pandas
Pandas — это мощная библиотека для обработки и анализа данных на Python. Одна из её функций — возможность легко идентифицировать уникальные элементы в датафреймах и рядах. Давайте рассмотрим два главных метода для этой задачи: unique() и nunique().
Для начала, давайте создадим тестовый DataFrame для демонстрации:
import pandas as pd
data = {
'City': ['NY', 'LA', 'SF', 'TX', 'LA', 'NY', 'TX'],
'Salary': [50000, 54000, 52000, 58000, 54000, 52000, 60000]
}
df = pd.DataFrame(data)Использование unique()
Метод unique() применяется к Series и возвращает массив уникальных элементов:
print(df['City'].unique())
# ['NY', 'LA', 'SF', 'TX']Заметьте, что порядок элементов в возвращаемом массиве будет соответствовать порядку их первого появления в исходной серии.
Использование nunique()
В то время как unique() возвращает все уникальные элементы, nunique() возвращает их количество:
print(df['City'].nunique())
# 4Если в данных есть пропущенные значения NaN, nunique() по умолчанию их игнорирует. Если вы хотите включить NaN в подсчет уникальных значений, используйте параметр dropna:
df['City_with_nan'] = ['NY', 'LA', None, 'TX', 'LA', 'NY', 'TX']
print(df['City_with_nan'].nunique(dropna=False))
# 4Работа с числовыми данными
Эти методы также применимы к числовым данным:
print(df['Salary'].unique())
# [50000, 54000, 52000, 58000, 60000]
print(df['Salary'].nunique())
# 5Применение на уровне DataFrame
Хотя обычно unique() и nunique() применяются к Series, вы можете использовать их и на уровне DataFrame, получая информацию по каждому столбцу:
print(df.nunique())
# City 4
# Salary 5
# dtype: int64Визуализация уникальных данных
Полученную информацию полезно визуализировать. Например, можно использовать график типа "bar" для отображения количества уникальных значений:
import pandas as pd
import matplotlib.pyplot as plt
data = {
'City': ['NY', 'LA', 'SF', 'TX', 'LA', 'NY', 'TX'],
'Salary': [50000, 54000, 52000, 58000, 54000, 52000, 60000]
}
df = pd.DataFrame(data)
df['City'].value_counts().plot(kind='bar')
plt.show()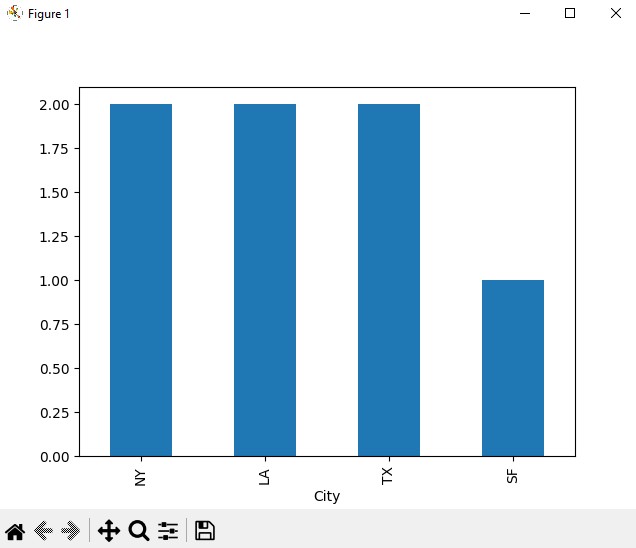
Исключение дубликатов с помощью drop_duplicates()
Помимо простого определения уникальных значений, иногда может понадобиться исключить дублирующиеся строки из DataFrame:
df.drop_duplicates(subset='City', keep='first', inplace=True)Здесь subset указывает на столбец, по которому проверяются дубликаты. Параметр keep может принимать значения first, last или False, что определяет, какой из дубликатов следует оставить (или удалять все дубликаты).
value_counts() для более детального анализа
Этот метод позволяет не только узнать уникальные значения, но и увидеть, сколько раз каждое из них встречается в Series:
print(df['City'].value_counts())
# City
# NY 2
# LA 2
# TX 2
# SF 1
# Name: count, dtype: int64Комбинирование методов для сложных запросов
Допустим, вы хотите узнать, сколько уникальных значений в столбце 'City' для тех, кто получает зарплату выше 52000:
print(df[df['Salary'] > 52000]['City'].nunique())
# 2Уникальные комбинации столбцов
Если вам нужно определить уникальные комбинации значений в нескольких столбцах:
unique_combinations = df[['City', 'Salary']].drop_duplicates()Таким образом, вы получите DataFrame, содержащий только уникальные комбинации 'City' и 'Salary'.
Учет NaN как уникального значения в unique()
В отличие от nunique(), метод unique() всегда будет возвращать NaN, если таковые присутствуют в данных:
df['City_with_nan'] = ['NY', 'LA', None, 'TX', 'LA', 'NY', 'TX']
print(df['City_with_nan'].unique())
# ['NY', 'LA', None, 'TX']Заключение
Работа с уникальными данными чрезвычайно важна, особенно при первичном анализе. Это может помочь понять распределение данных, выявить аномалии или дубликаты. С помощью unique() и nunique() в Pandas вы с легкостью сможете узнавать уникальные значения в ваших данных и их количество.
Содержание:


