


Как соединять таблицы в Pandas по разным критериям
- 15.11.2023
- 1437
- Библиотеки Python
- Pandas
Слияние данных — важная операция в анализе данных, которая позволяет объединять информацию из разных источников для получения более полного представления о данных. Рассмотрим метод merge() в библиотеке Pandas и различные типы соединений, которые позволяют эффективно объединять датасеты.
Основы метода merge()
Метод merge() в Pandas позволяет объединять два или более датасета на основе определенного столбца или набора столбцов. Он работает подобно операции SQL JOIN, что делает его мощным инструментом для агрегации и сопоставления данных.
Давайте начнем с основных параметров метода merge():
leftиright: это датасеты, которые мы хотим объединить.on: это столбец или список столбцов, по которым будет произведено соединение.how: это тип соединения, который определяет, какие строки будут включены в результат. Может принимать значенияinner,left,rightиouter.
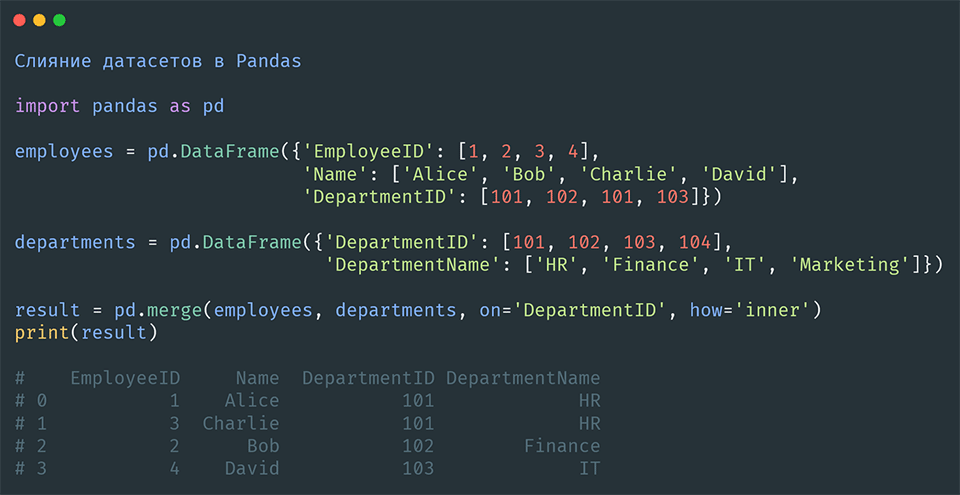
Давайте рассмотрим простой пример. У нас есть два датасета с информацией о сотрудниках и их отделах:
import pandas as pd
employees = pd.DataFrame({'EmployeeID': [1, 2, 3, 4],
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'DepartmentID': [101, 102, 101, 103]})
departments = pd.DataFrame({'DepartmentID': [101, 102, 103, 104],
'DepartmentName': ['HR', 'Finance', 'IT', 'Marketing']})Мы хотим объединить эти два датасета на основе столбца DepartmentID. Для этого мы используем метод merge():
result = pd.merge(employees, departments, on='DepartmentID', how='inner')
print(result)
# EmployeeID Name DepartmentID DepartmentName
# 0 1 Alice 101 HR
# 1 3 Charlie 101 HR
# 2 2 Bob 102 Finance
# 3 4 David 103 ITРезультат будет содержать информацию о сотрудниках и их отделах, объединенных на основе столбца DepartmentID.
Типы соединений
Существует несколько типов соединений, которые можно использовать с методом merge():
Внутреннее соединение (Inner Join)
Внутреннее соединение возвращает только те строки, для которых есть совпадение в обоих датасетах. В нашем примере внутреннее соединение вернет только сотрудников, у которых есть информация о отделе:
result = pd.merge(employees, departments, on='DepartmentID', how='inner')Левое соединение (Left Join)
Левое соединение возвращает все строки из левого датасета и соответствующие строки из правого датасета. Если нет соответствия в правом датасете, то будут добавлены пропущенные значения. В нашем примере левое соединение вернет всех сотрудников и их отделы, а также пропущенное значение для сотрудника David, у которого нет информации о отделе:
result = pd.merge(employees, departments, on='DepartmentID', how='left')
print(result)
# EmployeeID Name DepartmentID DepartmentName
# 0 1 Alice 101 HR
# 1 2 Bob 102 Finance
# 2 3 Charlie 101 HR
# 3 4 David 103 ITВнешнее соединение (Outer Join)
Внешнее соединение возвращает все строки из обоих датасетов. Если нет соответствия в одном из датасетов, то будут добавлены пропущенные значения. В нашем примере внешнее соединение вернет всех сотрудников и отделы, включая пропущенные значения для сотрудника David и отдела Marketing:
result = pd.merge(employees, departments, on='DepartmentID', how='outer')
print(result)
# EmployeeID Name DepartmentID DepartmentName
# 0 1.0 Alice 101 HR
# 1 3.0 Charlie 101 HR
# 2 2.0 Bob 102 Finance
# 3 4.0 David 103 IT
# 4 NaN NaN 104 MarketingДополнительные советы и приемы при слиянии данных
Помимо основных типов соединений и параметров метода merge(), существуют некоторые дополнительные советы и приемы, которые могут сделать слияние данных более продуктивным и эффективным:
Слияние по нескольким столбцам
Вы можете сливать данные не только по одному столбцу, но и по нескольким столбцам. Для этого просто передайте список столбцов в параметр on. Например, если у вас есть столбцы DepartmentID и Year, и вы хотите объединить данные по обоим столбцам, сделайте следующее:
result = pd.merge(employees, departments, on=['DepartmentID', 'Year'], how='inner')Использование индексов для слияния
Вместо столбцов вы также можете использовать индексы для слияния данных. Для этого установите параметр left_index или right_index в True, чтобы указать, что вы хотите использовать индекс соответствующего датасета для слияния. Например:
result = pd.merge(employees, departments, left_index=True, right_index=True, how='inner')Переименование столбцов перед слиянием
Иногда бывает полезно переименовать столбцы перед слиянием, чтобы избежать конфликтов и упростить анализ данных. Для этого используйте метод rename():
employees = employees.rename(columns={'EmployeeID': 'ID'})
departments = departments.rename(columns={'DepartmentID': 'ID'})
result = pd.merge(employees, departments, on='ID', how='inner')Избегание дубликатов
При слиянии данных иногда могут появляться дубликаты строк, особенно при использовании внешних соединений. Вы можете избежать дубликатов с помощью метода drop_duplicates(). Например:
result = pd.merge(employees, departments, on='DepartmentID', how='outer')
result = result.drop_duplicates()Обработка пропущенных значений
Если в ваших данных есть пропущенные значения, они могут повлиять на результат слияния. Вы можете использовать методы fillna() или dropna() для обработки пропущенных значений перед слиянием:
employees = employees.fillna({'DepartmentID': -1})
result = pd.merge(employees, departments, on='DepartmentID', how='inner')Работа с дублирующимися столбцами
Иногда при слиянии данных появляются столбцы с одинаковыми именами из разных датасетов. Если вам необходимо сохранить оба столбца, вы можете использовать параметр suffixes для добавления суффиксов к именам столбцов. Например:
result = pd.merge(employees, departments, on='DepartmentID', how='inner', suffixes=('_employee', '_department'))Это добавит суффиксы _employee и _department к столбцам, которые имеют конфликтующие имена.
Заключение
Метод merge() в Pandas — мощный инструмент для объединения данных из разных источников. Он позволяет выполнять различные типы соединений, обрабатывать конфликты и сливать данные таким образом, чтобы получить полное представление о данных. Знание основных типов соединений и их применение помогут вам эффективно анализировать и использовать данные в ваших проектах и исследованиях.
Содержание:


